Warning: package 'tidyr' was built under R version 4.1.1
Warning: package 'purrr' was built under R version 4.1.1
Warning: package 'stringr' was built under R version 4.1.1
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Step 2. Read in the data
mh <-read_csv("MillerHadenData.csv")
Rows: 25 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (5): Participant, Abil, IQ, Home, TV
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
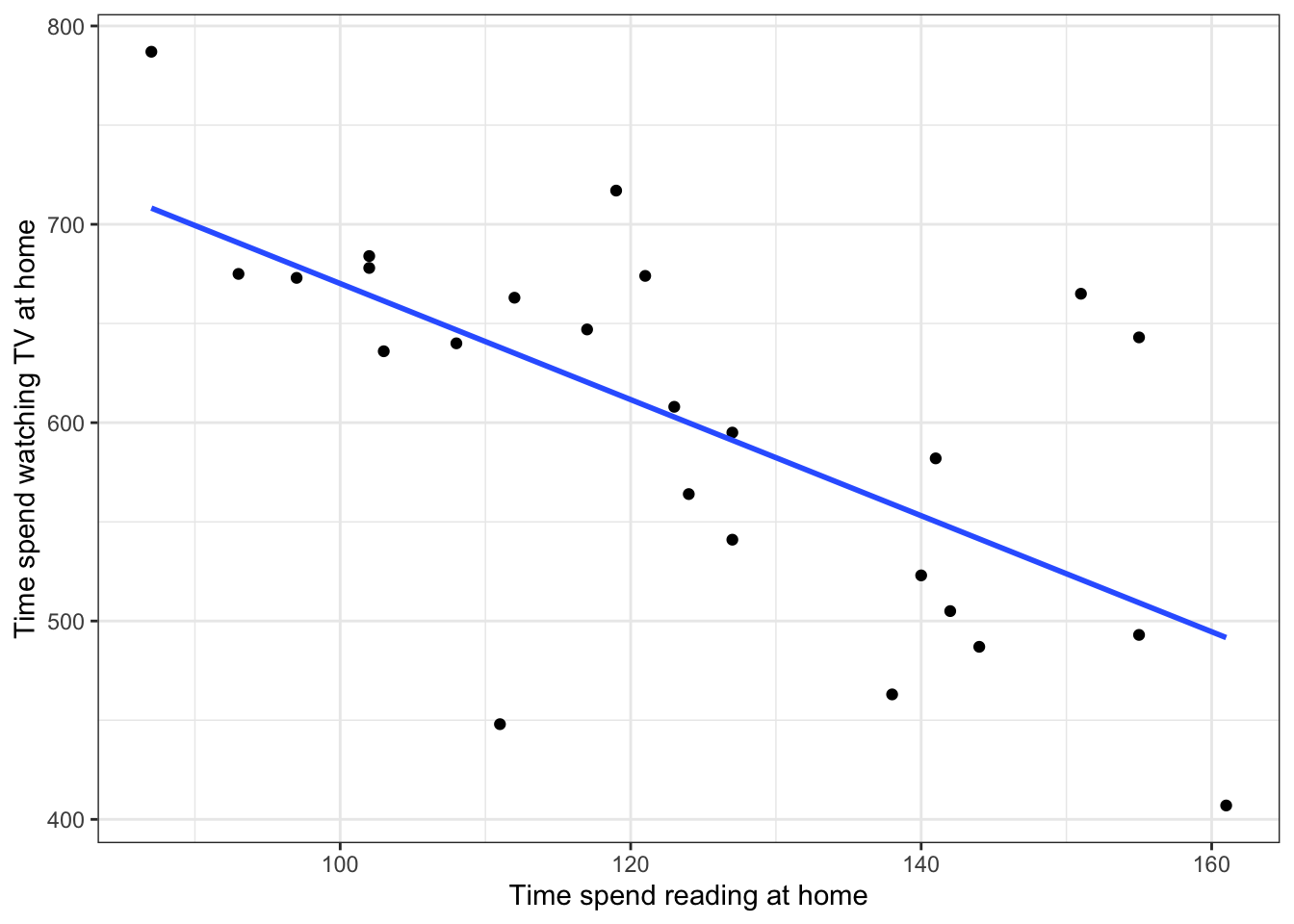
Step 3. Construct a scatterplot of the relationship between ‘Home’ and ‘TV’. Also add a line of best fit.
ggplot(mh, aes(x = Home, y = TV)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +theme_bw() +labs(x ="Time spend reading at home", y ="Time spend watching TV at home")
`geom_smooth()` using formula = 'y ~ x'
Question 3a: What can you tell from the scatterplot about the direction of the relationship?
Step 4. Conduct the correlation analysis.
results <-cor.test(mh$Home, mh$TV, method ="pearson", alternative ="two.sided") %>%tidy()results
Step 6. Write a few sentences in which you report this result, following APA guidelines.
“A Pearson’s correlation coefficient was used to assess the relationship between time spent reading at home and time spent watching TV at home. There was a significant negative correlation, r(23) = -.65, p < .001. As time spent watching TV increased, time spent reading at home decreased.”
Lab activity 3 - Hazardous alcohol use and impulsivity
Step 1. Read in the data
data <-read_csv("alcoholUse_Impulsivity.csv")
Rows: 20 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (3): participant, hau, imp
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
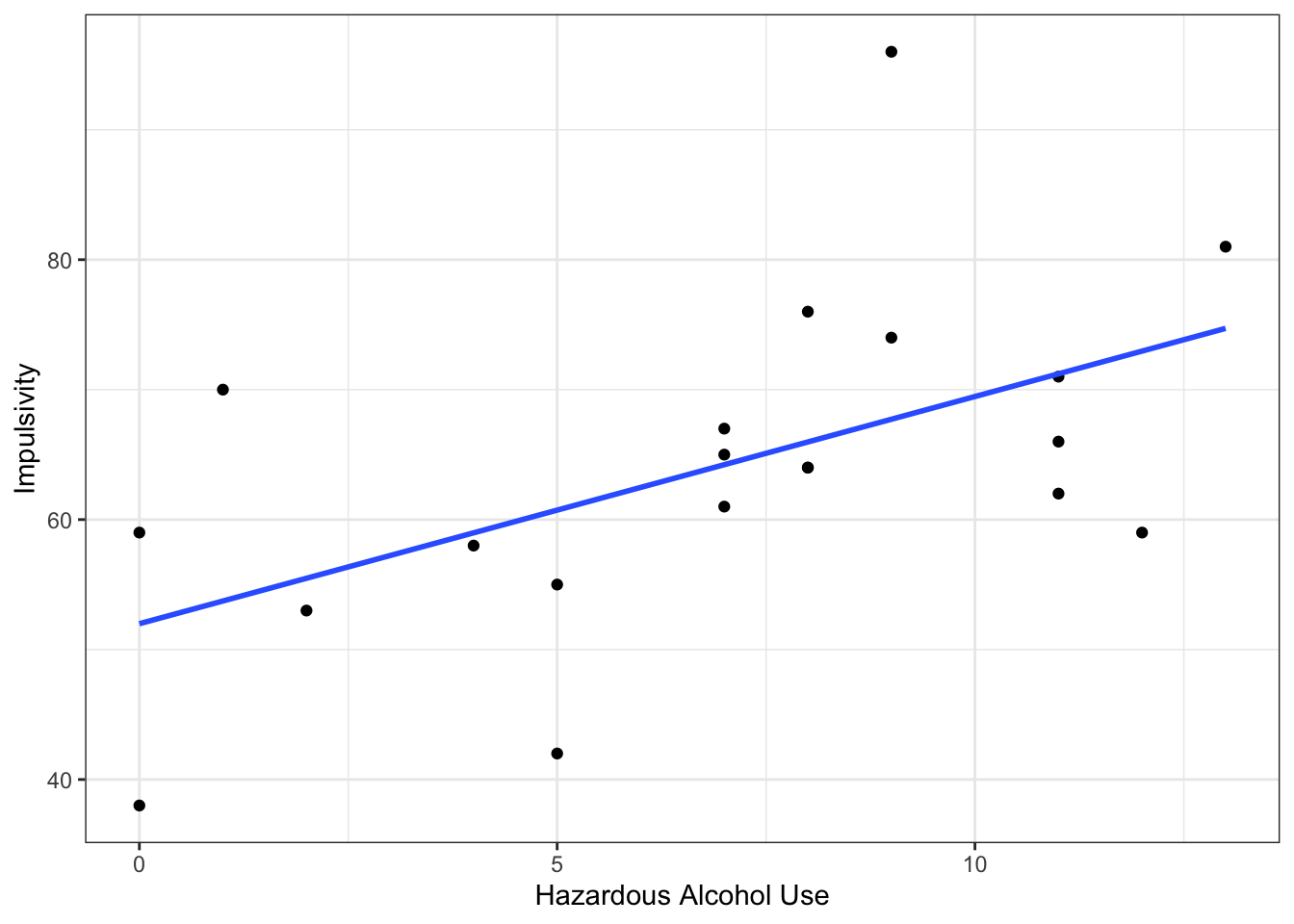
Step 2. Plot the relationship between hazard alcohol use and impulsivity using a scatterplot and a line of best fit
ggplot(data, aes(x = hau, y = imp)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +theme_bw() +labs(x ="Hazardous Alcohol Use", y ="Impulsivity")
`geom_smooth()` using formula = 'y ~ x'
Question 2a: What can you tell from the scatterplot about the direction of the relationship?
There is a positive association between ‘hazardous alcohol use’ and ‘impulsivity’. This means that as a participant’s score on ‘hazardous alcohol use’ goes up, their score on ‘impulsivity’ also goes up.
Step 3. Conduct a correlation analysis, using Pearson’s r
results <-cor.test(data$hau, data$imp, method ="pearson", alternative ="two.sided") %>%tidy()results
# pull out Pearson's r, the degrees of freedom and the p-value for reporting the resultsr <- results %>%pull(estimate) %>%round(2)df <- results %>%pull(parameter)pvalue <- results %>%pull(p.value) %>%round(3)rsquared <- r*rrsquaredPercent <-round(rsquared *100, 0)
Question 3a: What is the correlation coefficient (Pearson’s r)?
Question 3b: What is the p value?
Question 3c: Is the correlation significant at the p < .05 level?
Question 3d: What are the degrees of freedom you need to report?
Question 3e: How much variance in ‘impulsivity’ can be accounted for by ‘hazardous alcohol use’?
Question 3f: Give three logically possible directions of causality, indicating for each direction whether it is a plausible explanation in light of the variables involved (and why). No, this is not a trick question —-I know that correlation does not infer causation, but think critically! New studies/ideas are constructed by thinking what the previous study doesn’t tell us about what could be happening with the variables of interest.
Examples:
Being more impulsive may make people consume more alcohol.
Consuming more alcohol may make people more impulsive.
An outgoing personality might influence both your level of impulsivity and you are more likely to be socialising in the pub and consuming alcohol. So the same ‘third factor’ may influence both our variables of interest.
Step 4. Write a few sentences in which you report this result, following APA guidelines.
A Pearson’s correlation coefficient was used to assess the relationship between alcohol use and impulsivity. There was a significant positive correlation, r(18) = .54, p = .014. People who reported to consume more alcohol, scored higher on the impulsivity scale.