── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ dplyr::recode() masks car::recode()
✖ purrr::some() masks car::some()
✖ dplyr::src() masks Hmisc::src()
✖ dplyr::summarize() masks Hmisc::summarize()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Step 2. Read in the data
dat <-read_csv("VapingData.csv")
Rows: 166 Columns: 8
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Sex
dbl (7): Participant, IAT_BLOCK3_RT, IAT_BLOCK3_Acc, IAT_BLOCK5_RT, IAT_BLOC...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Question 2a: For how many participants do we have data?
There are 166 observations, so we have data for 166 participants. You can see this in the Environment window in the top right. This does not tell us whether any of these participants have any missing data.
Step 3. Data wrangling
dat <- dat %>%filter(IAT_BLOCK3_Acc <1) %>%# 1) only keep participants with accuracy scores equal to or smaller than 1 from block 3filter(IAT_BLOCK5_Acc <1) %>%# 1) only keep participants with accuracy scores equal to or smaller than 1 from block 5mutate(IAT_ACC = (IAT_BLOCK3_Acc + IAT_BLOCK5_Acc)/2) %>%# 2) calculate an average IAT accuracy score across blocks 3 and 5filter(IAT_ACC > .8) %>%# 2) only keep participants with an average score greater than .8.mutate(IAT_RT = IAT_BLOCK5_RT - IAT_BLOCK3_RT) # 3) compute the IAT_RT score
Question 3a: For how many participants do we have data now that we have cleaned them up?
104 participants.
Question 3b: Use the information in the background description to understand how the scores relate to attitudes. What does a positive IAT_RT score reflect? What does a negative IAT_RT score reflect? What does a higher score on the ‘VapingQuestionnaireScore’ mean?
People with a positive IAT_RT are considered to hold the implicit view that vaping is negative (i.e. congruent associations are quicker than incongruent associations).
People with a negative IAT_RT are considered to hold the implicit view that vaping is positive (i.e. incongruent associations were quicker than congruent associations).
Higher scores indicated a positive explicit attitude towards vaping.
Step 4: Calculating descriptive statistics
descriptives <- dat %>%summarise(n =n(),mean_IAT_ACC =mean(IAT_ACC),mean_IAT_RT =mean(IAT_RT),mean_VPQ =mean(VapingQuestionnaireScore, na.rm =TRUE))descriptives
# A tibble: 1 × 4
n mean_IAT_ACC mean_IAT_RT mean_VPQ
<int> <dbl> <dbl> <dbl>
1 104 0.916 185. 62.7
Question 4a: Why might these averages be useful? Why are averages not always useful in correlations?
It is always worth thinking about which averages are informative and which are not. Knowing the average explicit attitude towards vaping could well be informative. In contrast, if you are using an ordinal scale and people use the whole of the scale then the average may just tell you the middle of the scale you are using - which you already know and really isn’t that informative. So it is always worth thinking about what your descriptives are calculating.
Step 5: Check the assumptions
Variable types
Questions 5a: What are the variable types for the implicit (IAT_RT) and the explicit (VapingQuestionnaireScore) attitude variables?
Both can be considered continuous variables and at least at interval level.
Missing data
dat <- dat %>%filter(!is.na(VapingQuestionnaireScore)) %>%filter(!is.na(IAT_RT))
Question 5b How many people had missing data?
Before we removed participants with missing data, we had 104 observations, now we have 96. So there must have been 8 participants without a score on one or the other variable.
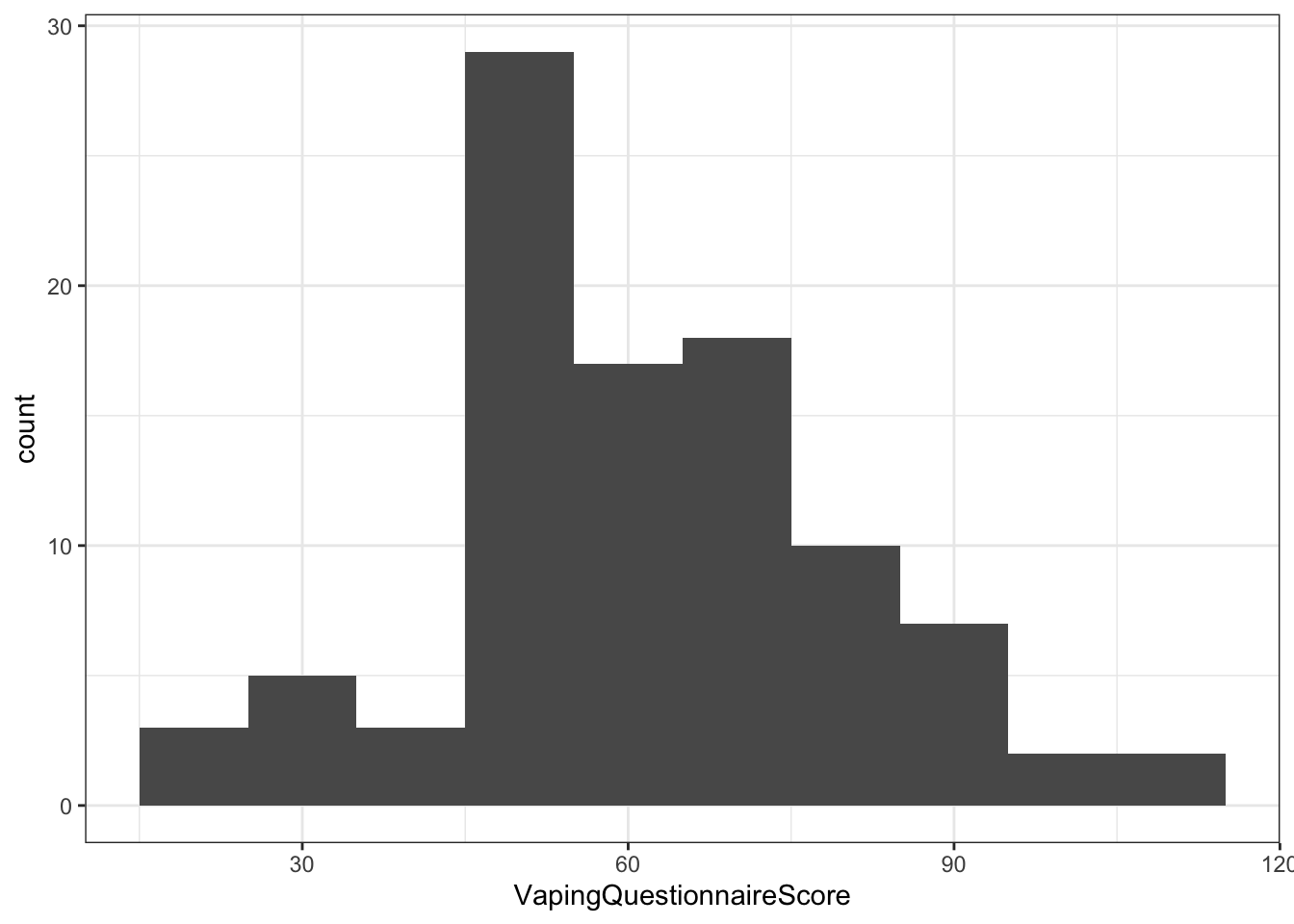
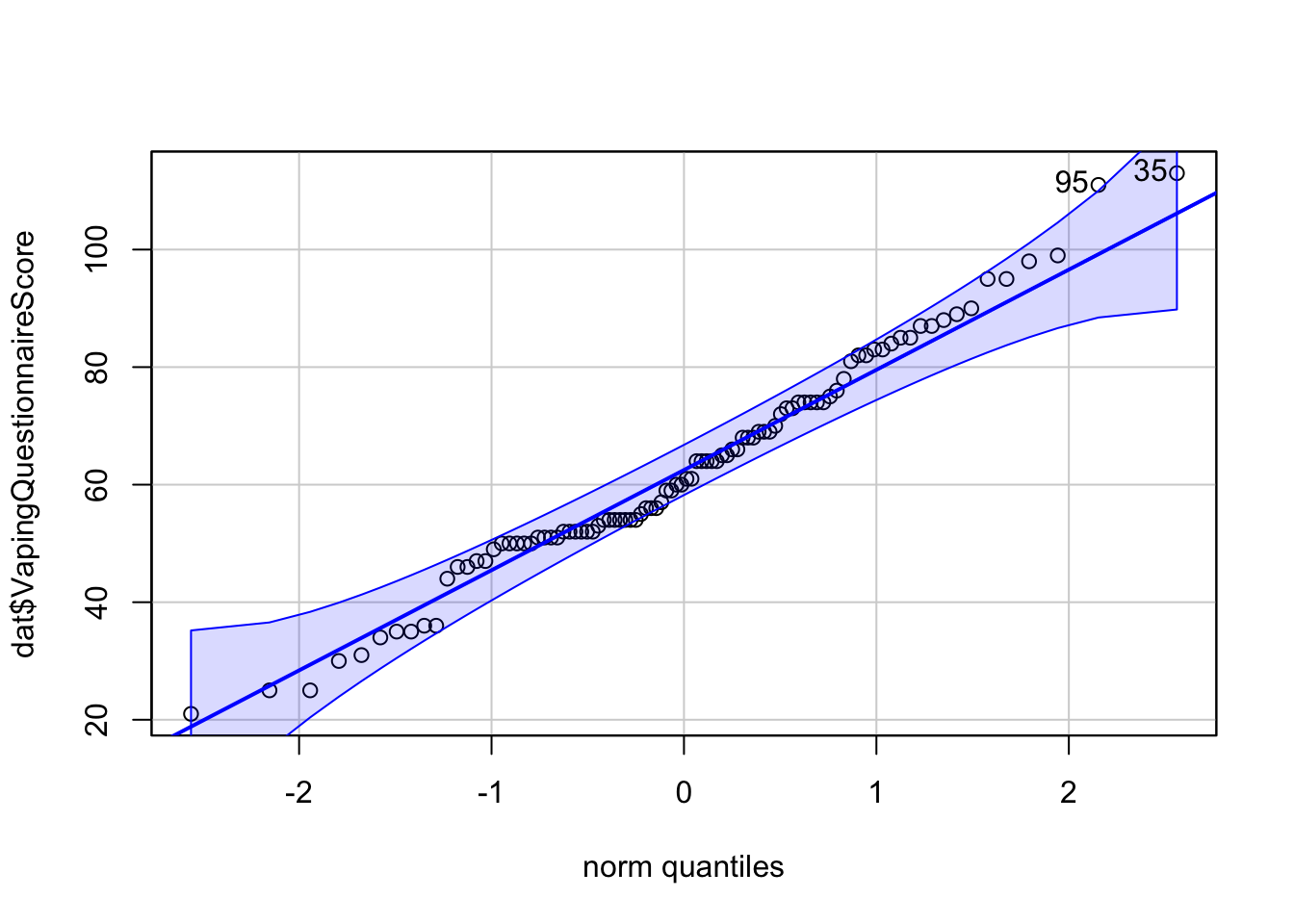
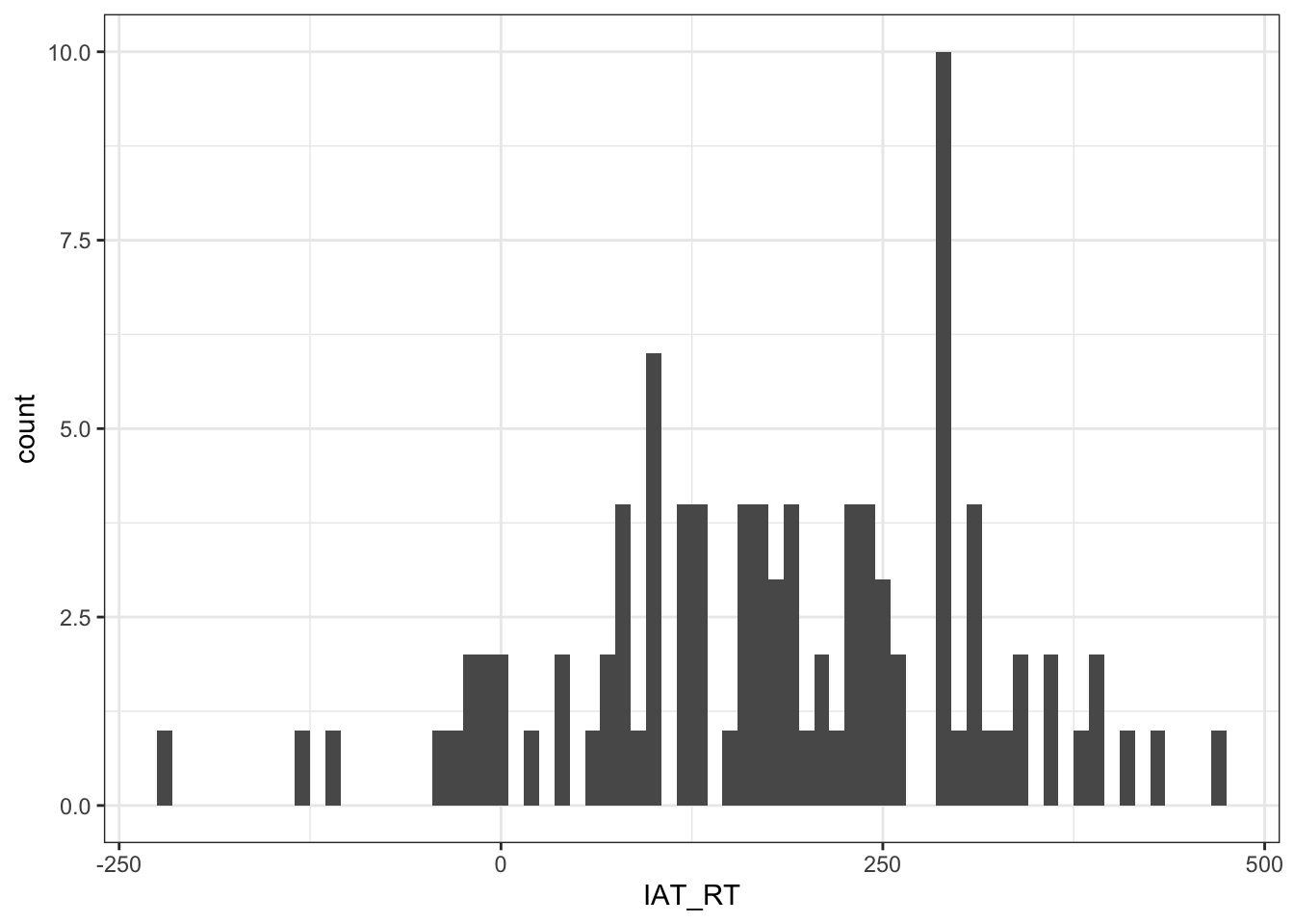
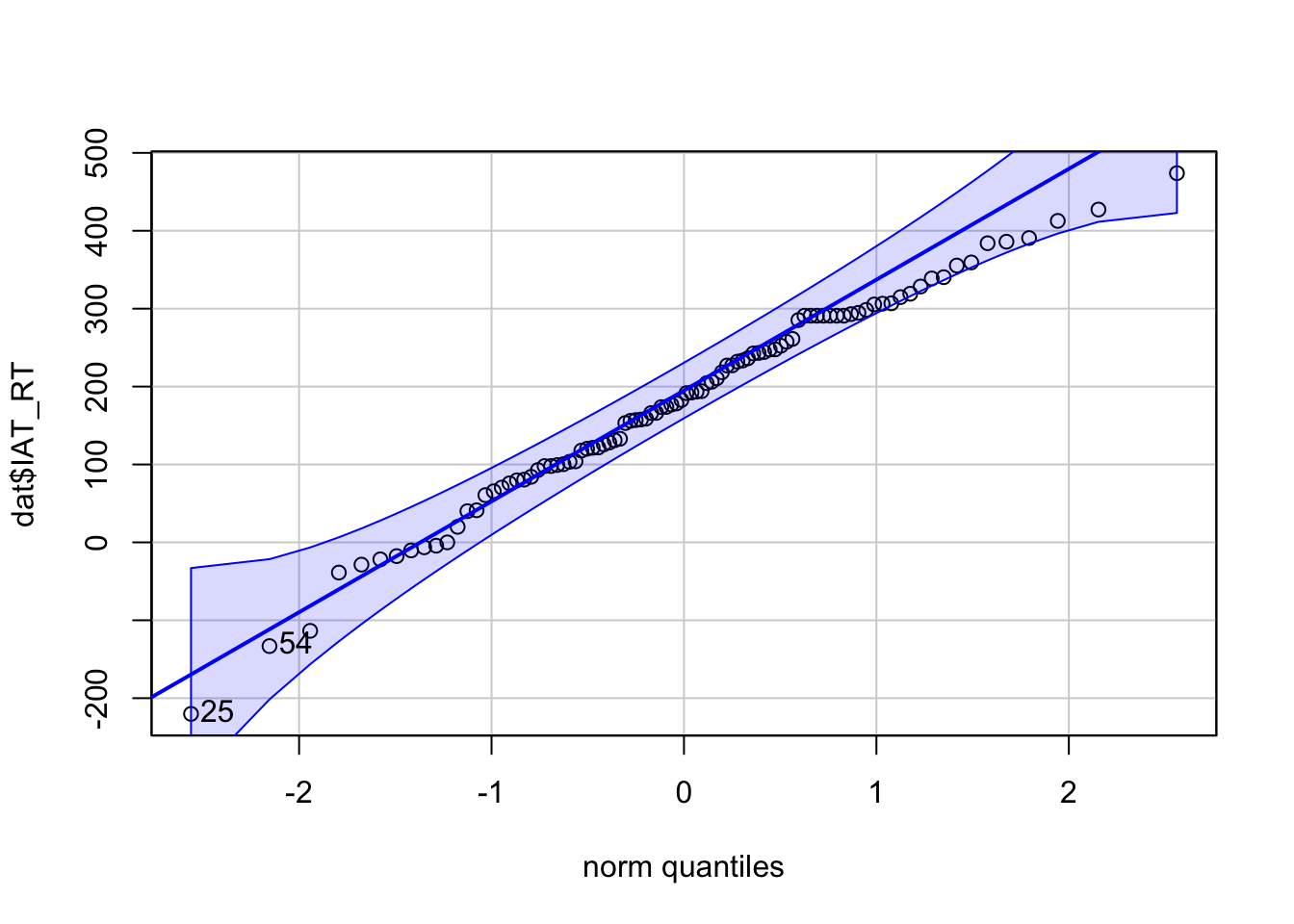
Question 5c What do you conclude from the histograms and the qq-plots? Are the VapingQuestionnaireScore and the IAT_RT normally distributed?
Yes. Both histograms resemble a normal distribution (bell curve) and the open circles in the qq-plots fall within the blue stripy lines.
Linearity and homoscedasticity
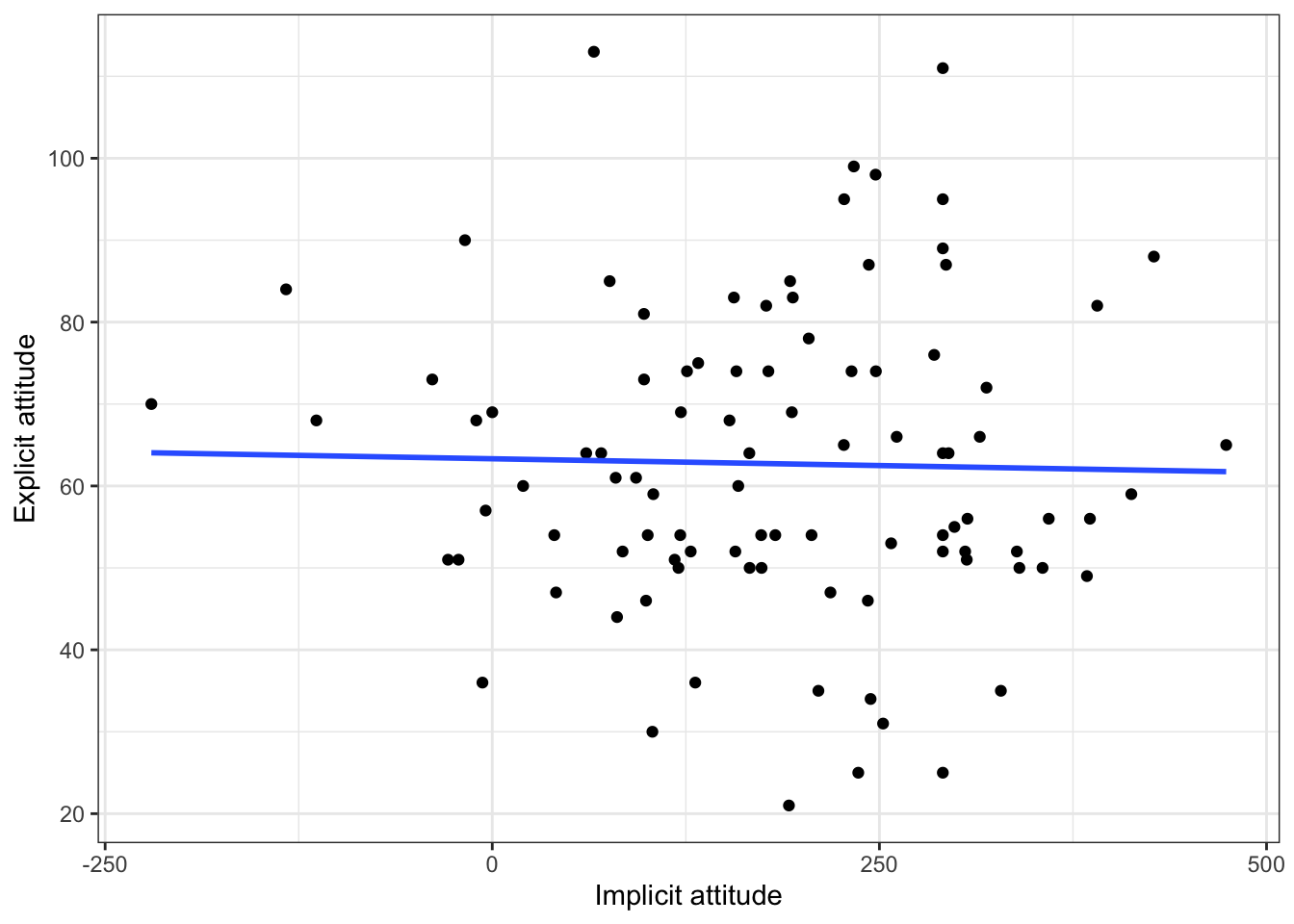
ggplot(dat, aes(x = IAT_RT, y = VapingQuestionnaireScore)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +theme_bw() +labs(x ="Implicit attitude", y ="Explicit attitude")
`geom_smooth()` using formula = 'y ~ x'
Question 5d What do you conclude from the scatterplot in terms of the homoscedasticity of the data and the linearity, direction and strength of the relationship? What does the scatterplot tell you about possible issues (outliers, range restrictions)?
The data look like a cloud without a clear direction. This suggests the relationship might might be weak. In terms of linearity, the scatterplot doesn’t suggest any curvilinear relationships. Variance seems quite constant, but there do seem to be few people with negative IAT_RT (Implicit attitude) scores, suggesting few people held the view that vaping is positive.
Step 6: Conduct a correlation analysis ———————————-
Question 6a Do you need to calculate Pearson’s r or Spearman’s rho? Why?
Pearson’s r because the data do meet the assumptions.
Testing the hypothesis of a relationship between implicit and explicit attitudes towards vaping, a Pearson correlation found no significant relationship between IAT reaction times (implicit attitude) and answers on a Vaping Questionnaire (explicit attitude), r(94) = -.02, p = .822. Overall this suggests that there is no direct relationship between implicit and explicit attitudes with regard to vaping and as such our hypothesis was not supported; we cannot reject the null hypothesis.
Step 8: Intercorrelations
Create a new data frame that only includes the relevant variables
dat_matrix <- dat %>%select(Age, IAT_RT, VapingQuestionnaireScore) %>%as.data.frame() # Make sure tell R that dat is a data frame
Create a matrix of scatterplots
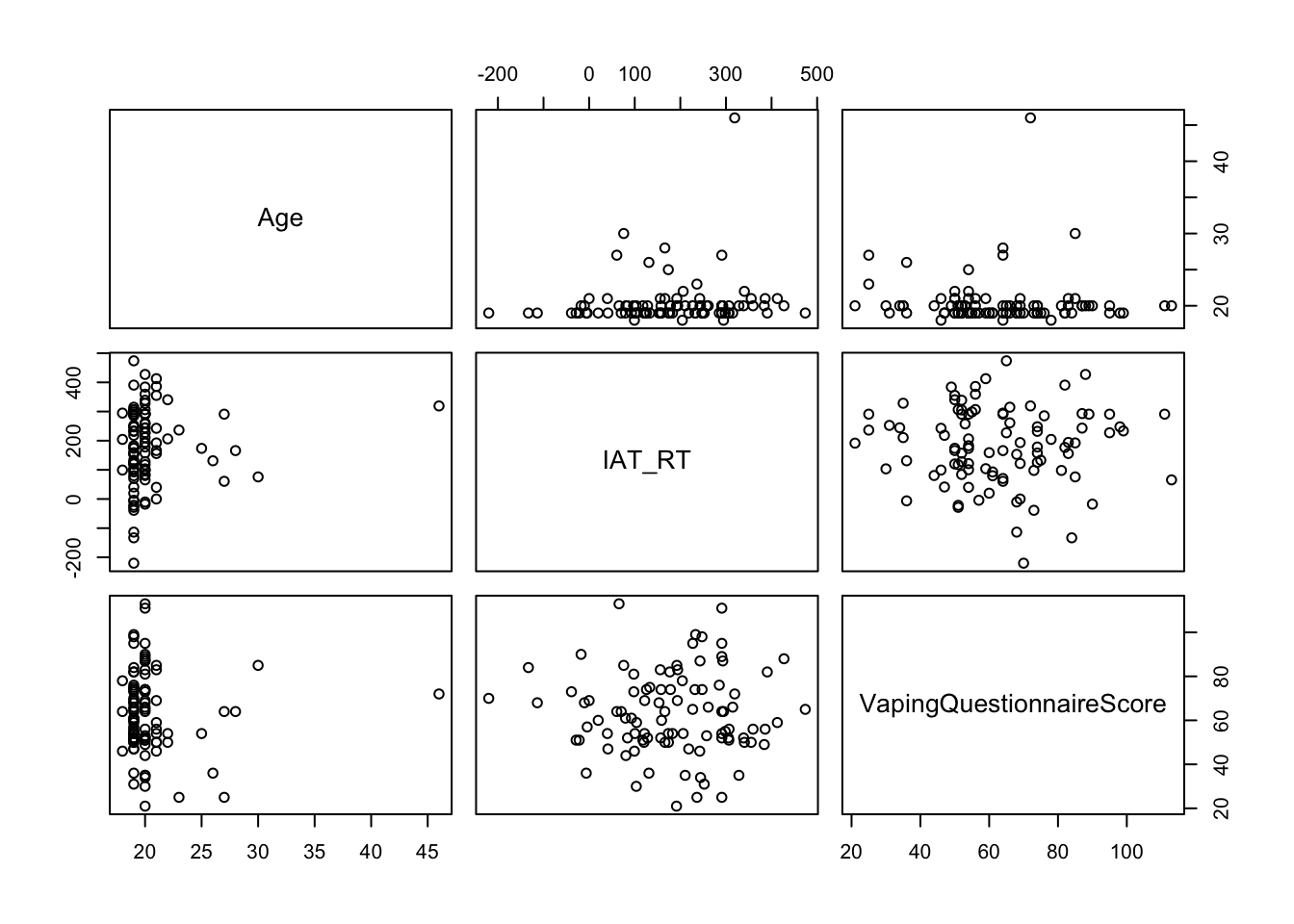
pairs(dat_matrix)
Question 8a What do you conclude from the scatterplots?
The scatterplots with age suggest that age is highly skewed with only a few participants older than 25. For now, let’s say we’ll therefore calculate Spearman’s rho, rather than Pearson’s r. That is ok for now, but if you were analysing these data for a research project, you’d want to have a closer look at the age variable (think histogram, qq-plot, and think about either collecting more data from older participants or transforming the variable (more about that next year).
Conduct intercorrelation (multiple correlations)
intercor_results <-correlate(x = dat_matrix, # our datatest =TRUE, # compute p-valuescorr.method ="spearman", # run a spearman test p.adjust.method ="bonferroni") # use the bonferroni correctionintercor_results
CORRELATIONS
============
- correlation type: spearman
- correlations shown only when both variables are numeric
Age IAT_RT VapingQuestionnaireScore
Age . 0.156 -0.086
IAT_RT 0.156 . -0.022
VapingQuestionnaireScore -0.086 -0.022 .
---
Signif. codes: . = p < .1, * = p<.05, ** = p<.01, *** = p<.001
p-VALUES
========
- total number of tests run: 3
- correction for multiple testing: bonferroni
- WARNING: cannot compute exact p-values with ties
Age IAT_RT VapingQuestionnaireScore
Age . 0.384 1.000
IAT_RT 0.384 . 1.000
VapingQuestionnaireScore 1.000 1.000 .
SAMPLE SIZES
============
Age IAT_RT VapingQuestionnaireScore
Age 96 96 96
IAT_RT 96 96 96
VapingQuestionnaireScore 96 96 96
Question 8b What do you conclude from the results of the correlation analysis?