Part 4 provides more practice running paired t-tests.
Part 5 presents some extras - exploring different datasets and running t-tests on those data.
5.4.1.1 Part 1: Revision
Task 1: Checklist: What I can now do
You should be able to answer yes to all the following. If you can’t yet, go back to the previous workbooks and repeat your working until you can answer yes, being able to type in and run the commands without referring to your notes.
I can open R-studio
I can open new libraries using library()
I can make an R script file
I can input a file into an object in R-studio using read_csv()
I can join two files together using inner_join()
I can select certain variables from an object using select()
I can select subsets of data using filter() (e.g., I can select participants in two conditions from a data set containing participants in four conditions)
I can make new variables using mutate()
I can arrange data according to subsets using group_by()
I can change format of data from wide to long format using pivot_longer
I can change format of data from long to wide format using pivot_wider
I can produce summaries of means and standard deviations for subsets of data after applying group_by() using summarise()
I can draw histograms of single variables, point plots of two ratio/interval/ordinal variables, bar plots of counts, and box plots of one categorical and one ratio/interval/ordinal variable using ggplot()
I can run a Chi-squared test and Cramer’s V test using chisq.test() and cramersV()
I can interpret the results of a Chi-squared test and Cramer’s V test and write up a simple report of the results.
I can save an R script file.
ANSWER
Here are some examples of the commands/functions in use:
rm(list=ls())library(tidyverse)
Warning: package 'ggplot2' was built under R version 4.4.3
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 4.0.1 ✔ tibble 3.2.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.0.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
# from week4 practicaldat <-read_csv("data/wk4/PSYC411-shipley-scores-anonymous-17_25_year_language.csv")
Rows: 293 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): english_status
dbl (6): subject_ID, Age, Shipley_Voc_Score, Gent_1_score, Gent_2_score, aca...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
dat$academic_year <-as.factor(dat$academic_year)#View(dat)# from week2 practicaldat2 <-read_csv("data/wk2/ahicesd.csv")
Rows: 992 Columns: 50
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (50): id, occasion, elapsed.days, intervention, ahi01, ahi02, ahi03, ahi...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
pinfo <-read_csv("data/wk2/participantinfo.csv")
Rows: 295 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (6): id, intervention, sex, age, educ, income
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Pearson's Chi-squared test
data: all_dat$occasion and all_dat$intervention
X-squared = 9.7806, df = 15, p-value = 0.8333
cramersV(x = all_dat$occasion, y = all_dat$intervention)
[1] 0.05732779
5.4.1.2 Part 2: Running an independent t-test
Task 2: Load, prepare, and explore the data
Clear out R using rm(list=ls())
Load again the data set on the Shipley and Gent vocabulary scores from week 4.
Set the research question: do people who self-identify as male or female have different scores on the Gent vocabulary test? The research hypothesis is: “People who identify as male or female have different vocabulary scores”. What is the null hypothesis?
Answer
There is no difference between people who self-identify as male or female on vocabulary scores.
To test the research hypothesis, we will filter people who self-identify as male or female from the data set. To be inclusive, additional research questions would be part of your research project to analyse also people who self-identify as other gender. Run this command to extract a subset of the data (note that the | stands for “or”, and means Gender matches male or gender matches female:
dat <-read_csv("data/wk4/PSYC411-shipley-scores-anonymous-17_25_gender.csv")
Rows: 293 Columns: 5
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Gender
dbl (4): subject_ID, Shipley_Voc_Score, Gent_1_score, Gent_2_score
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
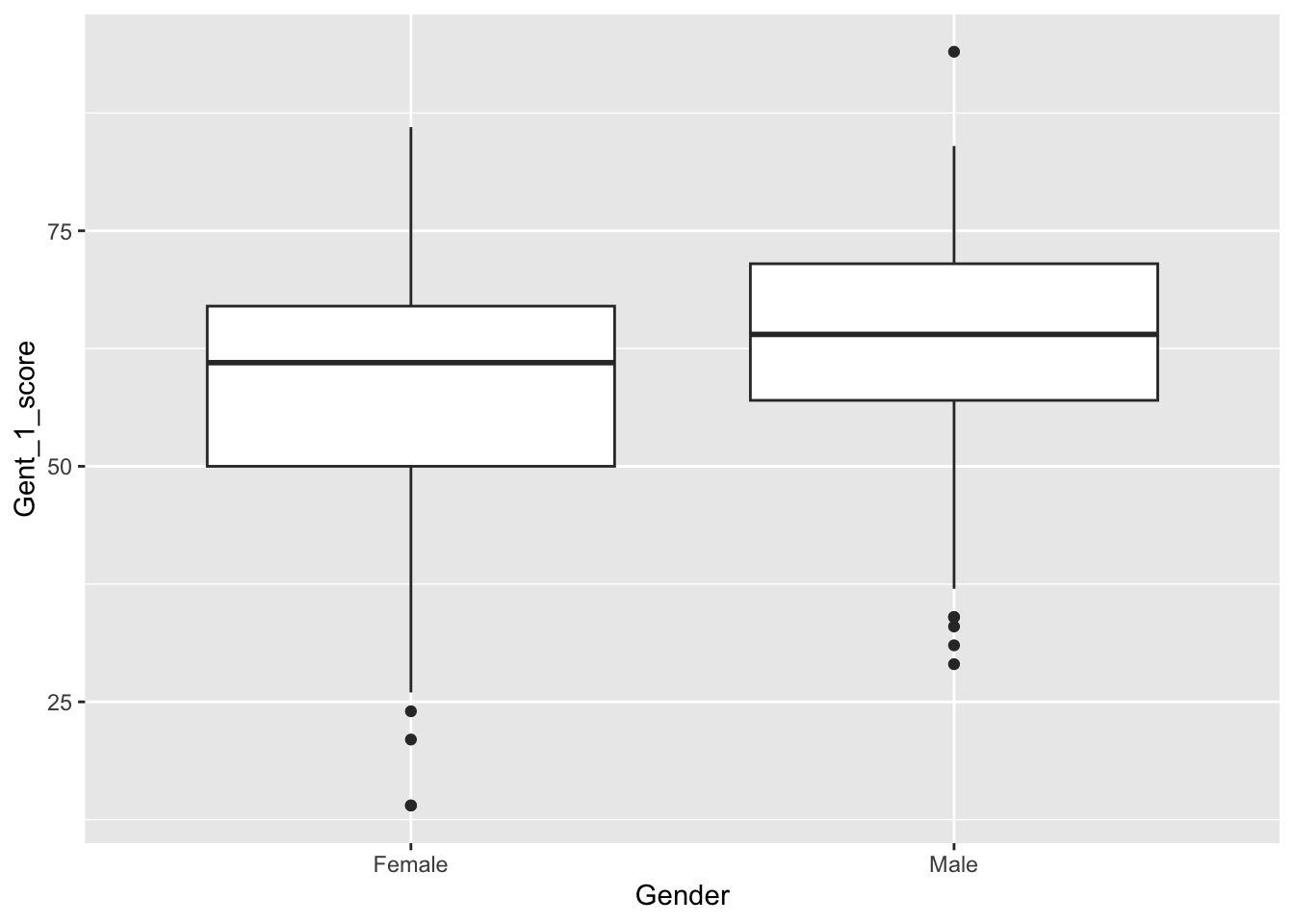
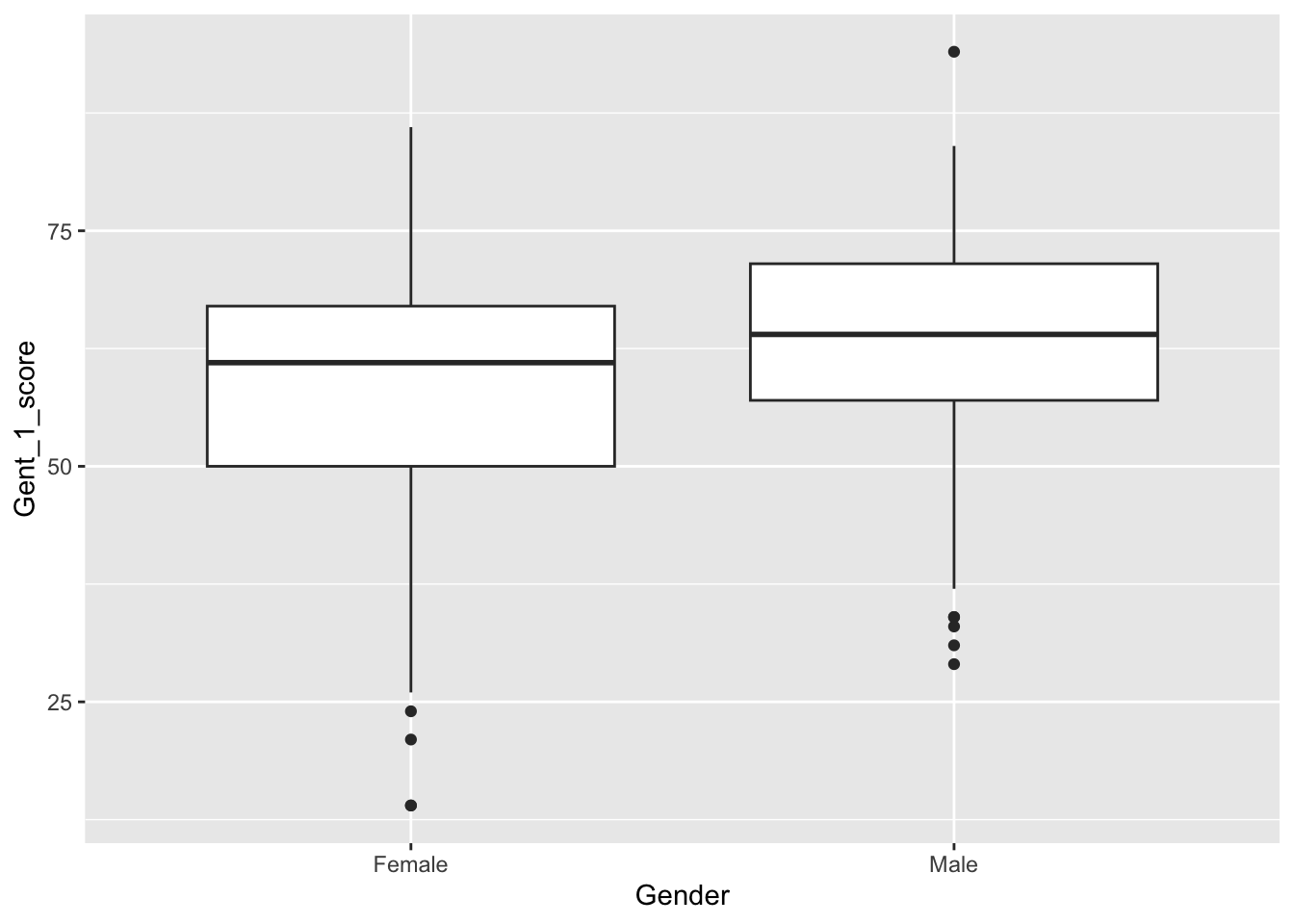
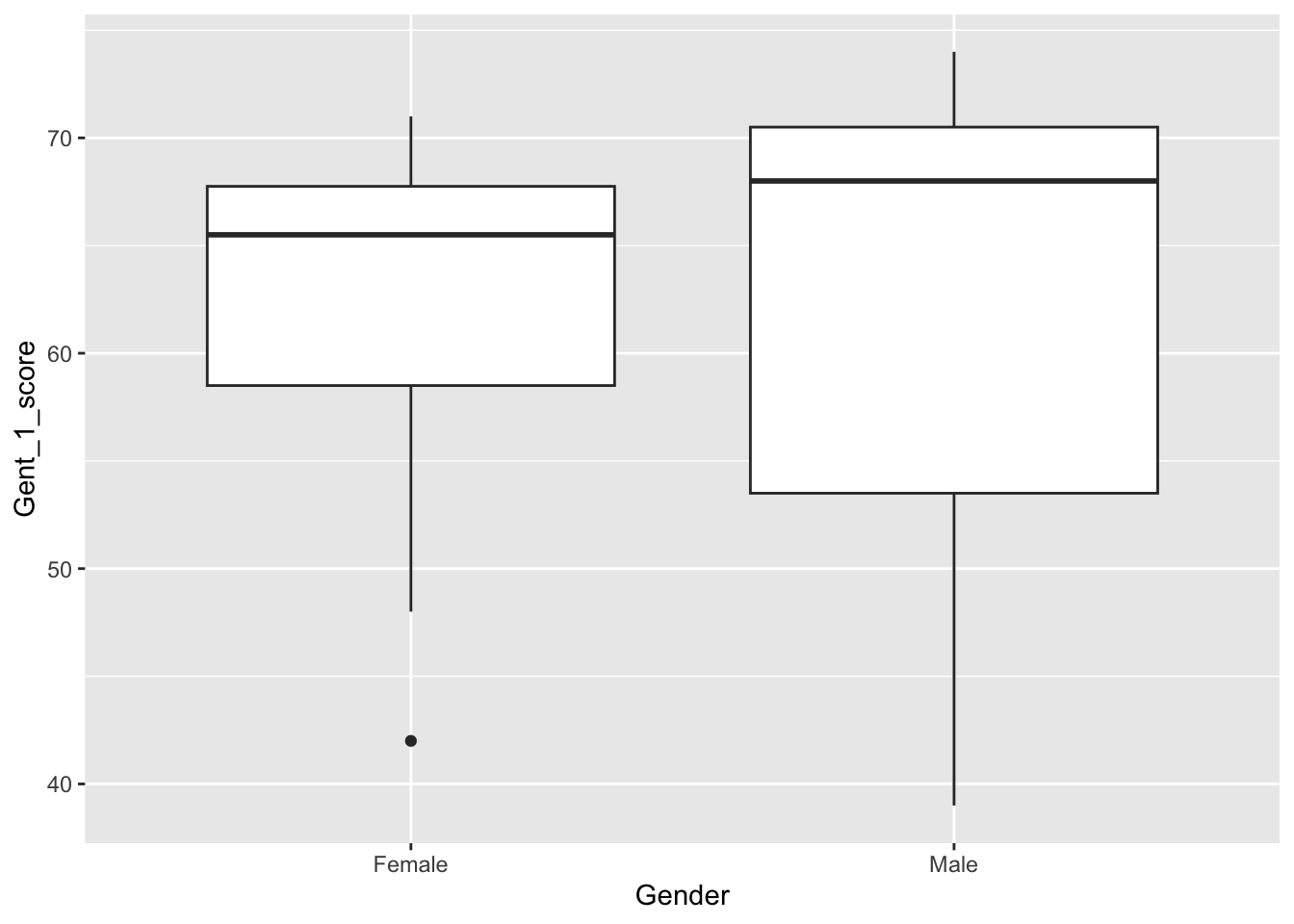
Draw a box plot of Gent vocabulary test 1 scores by gender. For a box plot, note that we need data in “long format”, where each observation is on one line, and we have a column that indicates which condition (in this case Gender) the participant is in. Does it look like there might be a gender effect? What is the direction of the effect?
Answer
ggplot(dat2, aes(x = Gender, y = Gent_1_score)) +geom_boxplot()
Warning: Removed 4 rows containing non-finite outside the scale range
(`stat_boxplot()`).
The graph indicates that maybe males are slightly higher, but looks like a lot of overlap.
Note that unless we had filtered the data, the box plot would contain ‘NA’ as well, which stands for missing data. In a data set it’s always a good idea to call missing data ‘NA’ rather than just leaving them blank because this could be interpreted as a zero or as an error of filling in data. Missing values make things untidy, so it’s good practice to focus only on the variables we need for the t-test and remove all other missing values. Use select() to get just the Gender and Gent_1_score variables, and put this in a new object called ‘dat3’.
Answer
dat3 <-select(dat2, Gender, Gent_1_score)
Next, in order to run a t-test we have to remove any rows of data which contain a ‘NA’ - either in the Gender or the Gent_1_score variables. We do this using drop_na(dat3), put the result in a new object called ‘dat4’. Run this command:
dat4 <-drop_na(dat3)
Now, redraw the box plot from Step 21. Check there are just two groups still.
Answer
ggplot(dat2, aes(x = Gender, y = Gent_1_score)) +geom_boxplot()
Warning: Removed 4 rows containing non-finite outside the scale range
(`stat_boxplot()`).
Yes, two groups.
Compute mean and SDs for people who self-identify as male or female on Gent vocabulary test 1 scores.
# A tibble: 2 × 3
Gender `mean(Gent_1_score)` `sd(Gent_1_score)`
<chr> <dbl> <dbl>
1 Female 59.0 13.7
2 Male 62.3 13.7
# Or, if you know how to use the %>% (pipe) ...:dat4 %>%group_by(Gender) %>%summarise(mean(Gent_1_score), sd(Gent_1_score))
# A tibble: 2 × 3
Gender `mean(Gent_1_score)` `sd(Gent_1_score)`
<chr> <dbl> <dbl>
1 Female 59.0 13.7
2 Male 62.3 13.7
Task 3: Run the independent t-test and measure effect size
Conduct an independent t-test using this command:
t.test(Gent_1_score ~ Gender, data = dat4 )
‘Gent_1_score ~ Gender’ : the ~ can be interpreted as ‘by’, i.e., compute Gent_1_score by Gender
The results should look like this, do yours?
Welch Two Sample t-test
data: Gent_1_score by Gender
t = -1.7019, df = 100.37, p-value = 0.09187
alternative hypothesis: true difference in means between group Female and group Male is not equal to 0
95 percent confidence interval:
-7.2386790 0.5537475
sample estimates:
mean in group Female mean in group Male
58.99087 62.33333
The key part of the results to look at is the one that has t = -1.7019, df = 100.37, p-value = 0.09187. This is the result that you report: t(100.37) = -1.70, p = .092.
The value is negative because the function includes Female before Male - and Female score is lower than Male score. What matters is how far away from zero the t-test is (either positively or negatively). The df value is slightly odd because the t.test() function figures out degrees of freedom in a technical way which takes into account differences in variance in the data between the two groups. We can just use the value that the t.test() function gives us.
Is this a significant difference?
Answer
No, it isn’t. The p-value is greater than 0.05.
Now we need to compute the effect size, using Cohen’s d. You need to load the library lsr then use this command:
cohensD(Gent_1_score ~ Gender, method ="unequal", data = dat4)
It’s pretty much the same as the t-test() command except that we use ‘method = ’unequal’. For a paired t-test you would use ‘method = ’paired’
What is the effect size? Make a brief report of the results - reporting means and SDs, the t-test, p-value, and Cohen’s d. Discuss your brief report in your group.
Answer
d = 0.24
An ideal brief report of the results would state what the research question/hypothesis is, describe the means and SDs of the groups being compared, and then report the t-test statistic, with p-value and Cohen’s d effect size, then provide a brief interpretation of what the results mean.
Based on Hyde and Linn (1988), we hypothesised that people who self-identify as female may score slightly higher than males in terms of vocabulary scores. Males (mean = 62.33, SD = 13.74) scored higher than females (mean = 58.99, SD = 13.72) on the first time participants attempted the Gent vocabulary test, however this difference was not significant, t(100.37) = -1.70, p = .092, Cohen’s d = 0.24. We did not find evidence to support the hypothesis.
Reference
Hyde, J. S., & Linn, M. C. (1988). Gender differences in verbal ability: A meta-analysis. Psychological Bulletin, 104(1), 53–69. https://doi.org/10.1037/0033-2909.104.1.53
Make sure all commands are in the source window, save them as a new R script file.
Task 4: Practise running another independent t-test
Next research question: do people who are native English speakers have different vocabulary scores than those who learned English as a second language? What is the research hypothesis and the null hypothesis?
Answer
Research Hypothesis: People who speak English as a native language have higher vocabulary scores than those with English as a second language.
Null Hypothesis: There is no difference in vocabulary scores between native English and second language English speakers.
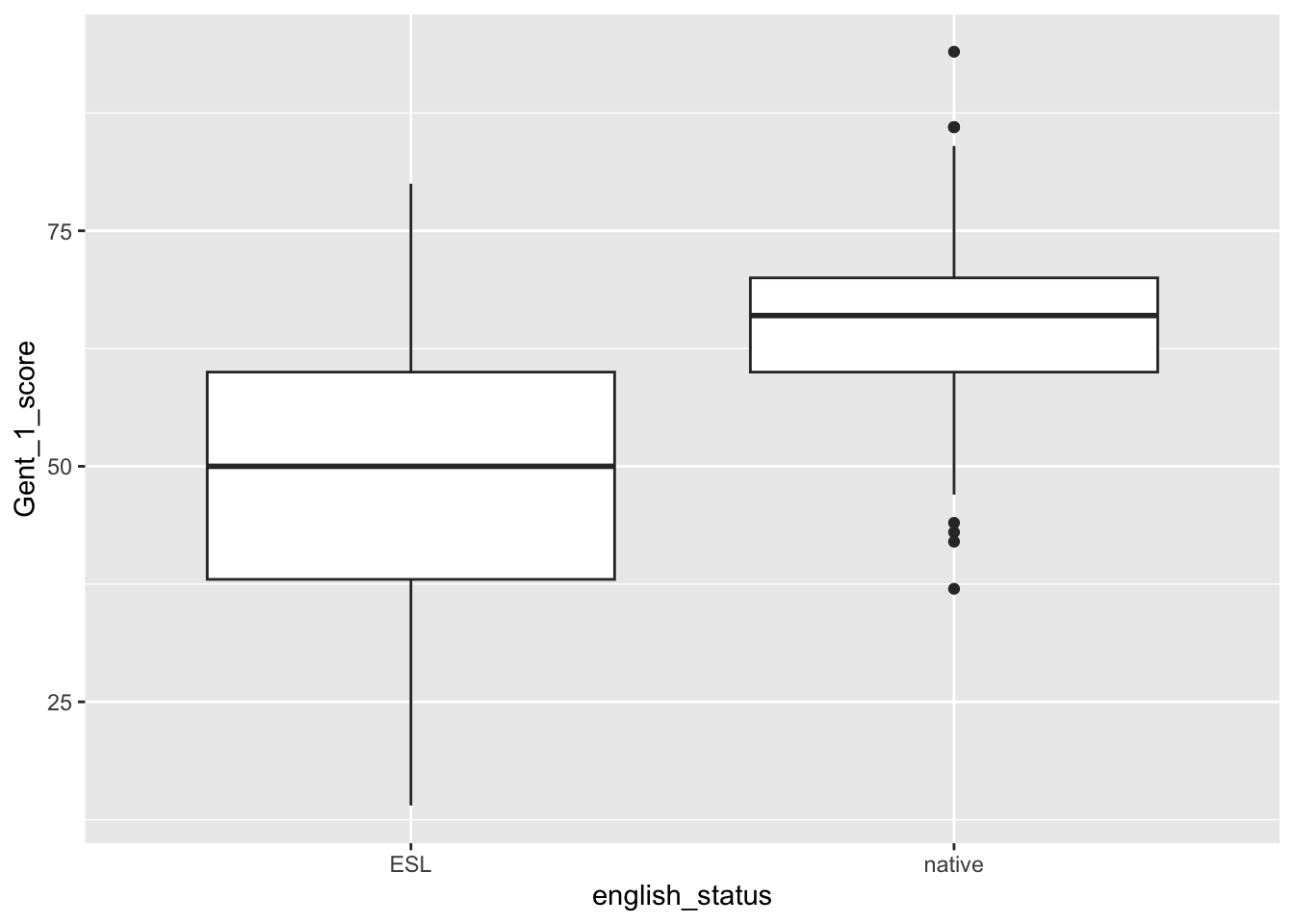
Repeat the Steps 22-30 in Tasks 2 and 3 except using english_status in place of Gender throughout.
Answer
dat <-read_csv("data/wk4/PSYC411-shipley-scores-anonymous-17_25_year_language.csv")
Rows: 293 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): english_status
dbl (6): subject_ID, Age, Shipley_Voc_Score, Gent_1_score, Gent_2_score, aca...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
t.test(Gent_1_score ~ english_status, data = dat3 )
Welch Two Sample t-test
data: Gent_1_score by english_status
t = -9.0756, df = 142.81, p-value = 8.239e-16
alternative hypothesis: true difference in means between group ESL and group native is not equal to 0
95 percent confidence interval:
-18.37748 -11.80381
sample estimates:
mean in group ESL mean in group native
50.04902 65.13966
cohensD(Gent_1_score ~ english_status, method ="unequal", data = dat3 )
[1] 1.19691
Write a brief report of the results, including means and SDs for native speakers and ESL speakers, t-test, p-value, and Cohen’s d. Discuss your report in your group.
Answer
We hypothesised that English as an additional language would result in lower overall vocabulary scores than English as a first language, because of the relation between length of time learning a language and language skills (Davies et al., 2017). Native English speakers (mean = 65.14, SD = 9.14) scored significantly higher on the Gent vocabulary test than speakers of English as a second language (mean = 50.05, SD = 15.31), t(142.81) = -9.08, p < .001, Cohen’s d = 1.20, a large effect size. Thus, the hypothesis was supported, with native English speakers scoring significantly higher on the Gent vocabulary test than those with English as an additional language.
Reference
Davies, R. A. I., Arnell, R., Birchenough, J., Grimmond, D., & Houlson, S. (2017). Reading Through the Life Span: Individual Differences in Psycholinguistic Effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43(8), 1298-1338. https://doi.org/10.1037/xlm0000366
Save your R script file.
5.4.1.3 Part 3: Conducting a paired t-test
Task 5: Conducting a paired t-test
Clear out R-studio before we get started again using rm(list=ls())
We are going to investigate again the data from this paper: Woodworth, R.J., O’Brien-Malone, A., Diamond, M.R. and Schuez, B., 2017. Data from, “Web-based Positive Psychology Interventions: A Reexamination of Effectiveness”. Journal of Open Psychology Data, 6(1).
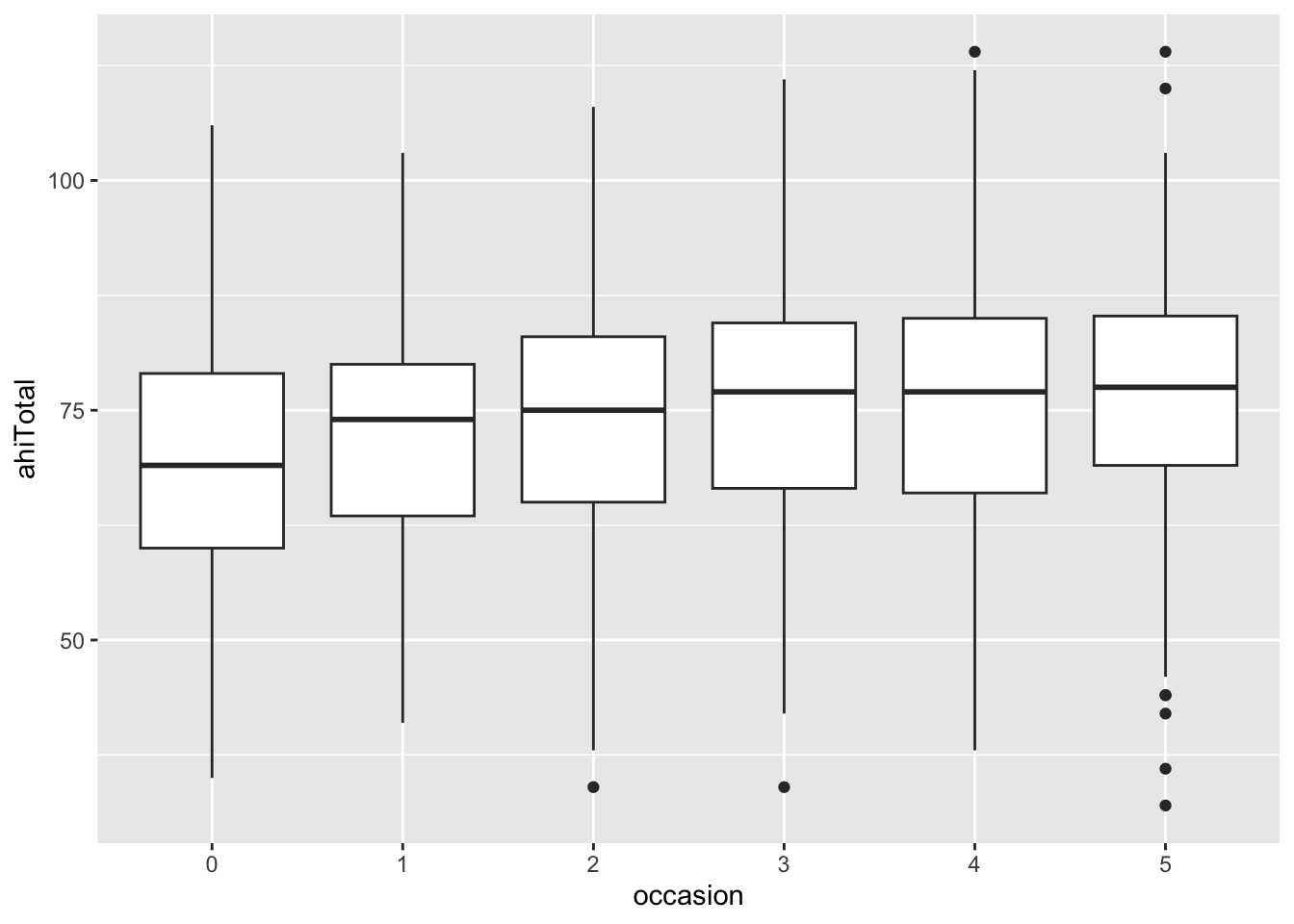
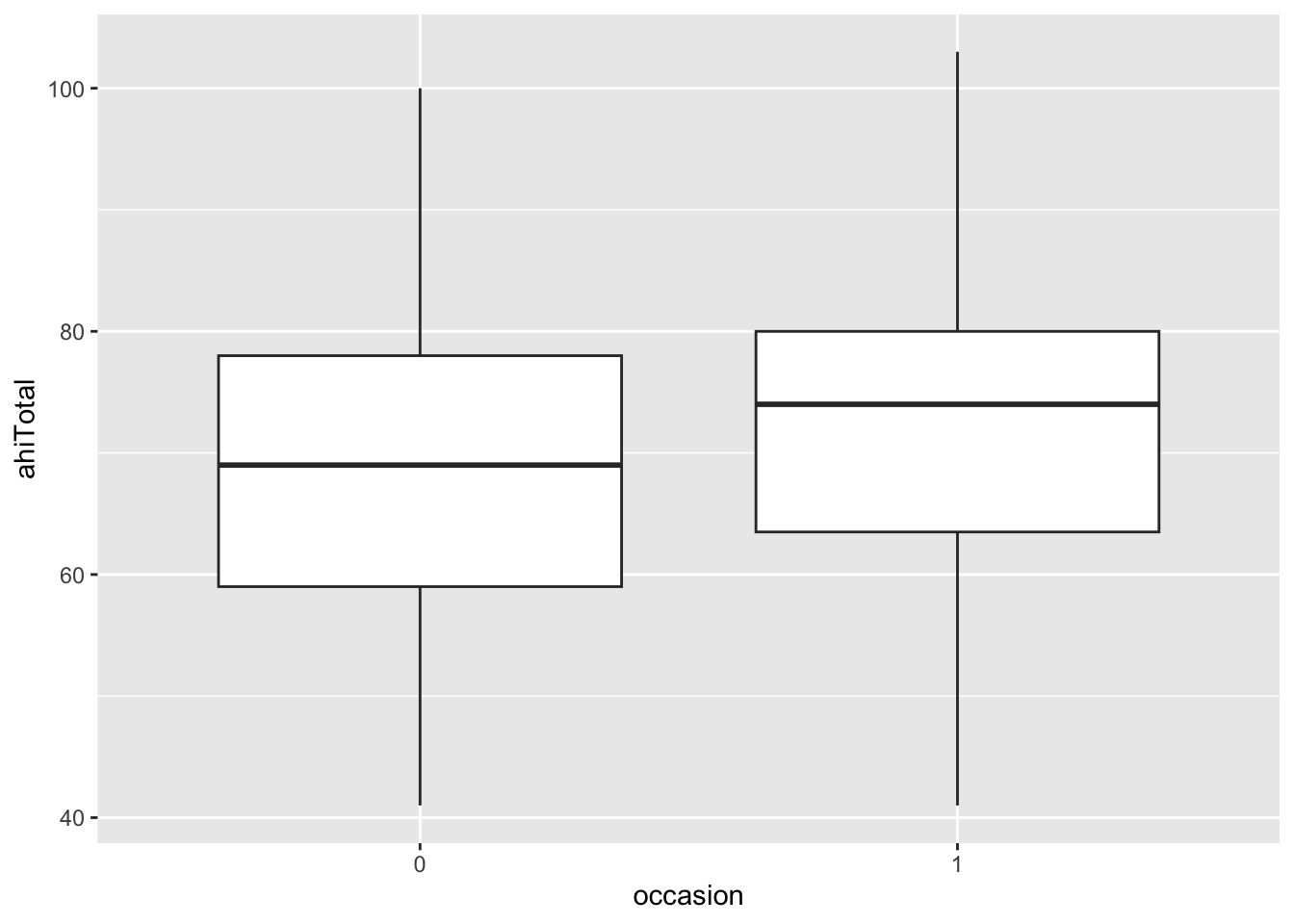
Our research question is whether happiness scores are affected by the interventions. We will look at the pre-test (occasion 0) and the first test after the intervention (occasion 1).
What is the research hypothesis and what is the null hypothesis?
Answer
RH: happiness scores change (increase) from the first to the second occasion of testing.
NH: happiness scores do not change across occasions.
Once again, join the ahicesd.csv and participantinfo2.csv data in R-studio by aligning the names for the participant numbers in these two data sets (see week 2 workbook for reminders about this).
Rows: 992 Columns: 50
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (50): id, occasion, elapsed.days, intervention, ahi01, ahi02, ahi03, ahi...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
pinfo <-read_csv("data/wk5/participantinfo2.csv")
New names:
Rows: 147 Columns: 7
── Column specification
──────────────────────────────────────────────────────── Delimiter: "," dbl
(7): ...1, id, intervention, sex, age, educ, income
ℹ Use `spec()` to retrieve the full column specification for this data. ℹ
Specify the column types or set `show_col_types = FALSE` to quiet this message.
• `` -> `...1`
all_dat <-inner_join(x = dat, y = pinfo, by =c("id", "intervention"))
Let’s select only the relevant variables. Use select() to select only id, ahiTotal, and occasion variables, and save this as a new object called ‘summarydata’
In order to run the paired t-test, we first need to make sure that the paired values (in this case the measures from the same person) are on the same row of the data. So, let’s use pivot_wider to put the ahiTotal scores for occasion 0 in one column, and the ahiTotal scores for occasion 1 in another column:
Write up a brief report of the result and discuss in your group.
Answer
We tested whether participants’ happiness scores at first testing after the interventions were different than their scores prior to the interventions. We found that, prior to the intervention, scores were significantly lower (M = 69.3, SD = 12.3) than they were immediately after the interventions (M = 72.4, SD = 12.6), t(146) = = 4.92, p < .001, Cohen’s d = 0.41, a medium effect. The results indicate that the intervention had a positive effect on happiness scores.
Save your R script file.
5.4.1.4 Part 4: More practice running a paired t-test
We are going to figure out whether people have different scores the first and second time they take the Gent vocabulary test.
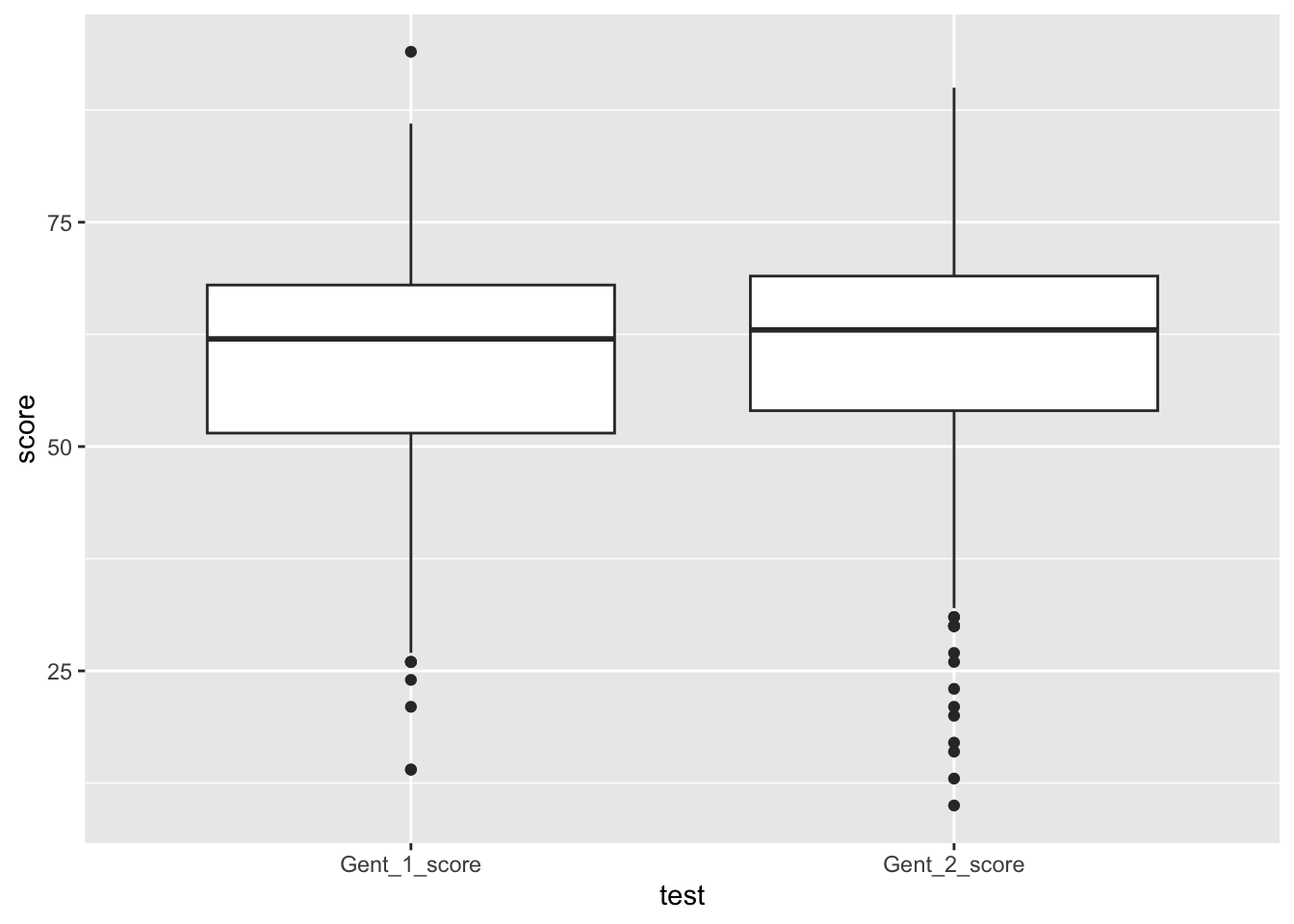
Go back to the vocabulary scores data. Load the data into dat, and make another object dat2 that contains only the subject_ID, Gent_1_score and Gent_2_score.
Some people did not do all the tests - look at participant 46 for instance. To do a t-test we need data where the person does both tests. We can filter out the scores where there are no NAs by repeating the drop_na we did at step 23, above. Call the new data object dat3.
Answer
dat <-read_csv("data/wk4/PSYC411-shipley-scores-anonymous-17_25_year_language.csv")
Rows: 293 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): english_status
dbl (6): subject_ID, Age, Shipley_Voc_Score, Gent_1_score, Gent_2_score, aca...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Paired t-test
data: dat3$Gent_1_score and dat3$Gent_2_score
t = -2.2279, df = 269, p-value = 0.02672
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-2.2744165 -0.1403983
sample estimates:
mean difference
-1.207407
In order to draw a box plot of the Gent vocabulary scores taken at the first and second occasion, we will need the data in “long format”, so that there is a column saying which test it is and a column reporting the scores on the Gent tests. Apply the pivot_longer command and then draw the box plot.
In the Gent vocabulary scores data, is there a significant difference between native and ESL speakers for your academic year group?
Answer
dat <-read_csv("data/wk4/PSYC411-shipley-scores-anonymous-17_25_year_language.csv")
Rows: 293 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): english_status
dbl (6): subject_ID, Age, Shipley_Voc_Score, Gent_1_score, Gent_2_score, aca...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
t.test(Gent_1_score ~ english_status, data = dat2 )
Welch Two Sample t-test
data: Gent_1_score by english_status
t = -0.37049, df = 10.511, p-value = 0.7184
alternative hypothesis: true difference in means between group ESL and group native is not equal to 0
95 percent confidence interval:
-8.282346 5.907346
sample estimates:
mean in group ESL mean in group native
63.0000 64.1875
cohensD(Gent_1_score ~ english_status, method ="unequal", data = dat2 )
[1] 0.1711966
t.test(Gent_2_score ~ english_status, data = dat2 )
Welch Two Sample t-test
data: Gent_2_score by english_status
t = -0.54825, df = 13.205, p-value = 0.5927
alternative hypothesis: true difference in means between group ESL and group native is not equal to 0
95 percent confidence interval:
-6.696472 3.982186
sample estimates:
mean in group ESL mean in group native
63.14286 64.50000
cohensD(Gent_2_score ~ english_status, method ="unequal", data = dat2 )
[1] 0.2415341
t.test(Gent_2_score ~ english_status, data = dat2 )
Welch Two Sample t-test
data: Gent_2_score by english_status
t = -0.54825, df = 13.205, p-value = 0.5927
alternative hypothesis: true difference in means between group ESL and group native is not equal to 0
95 percent confidence interval:
-6.696472 3.982186
sample estimates:
mean in group ESL mean in group native
63.14286 64.50000
cohensD(Gent_2_score ~ english_status, method ="unequal", data = dat2 )
[1] 0.2415341
nothing significant…
Are there significant differences for the Shipley vocabulary test measures between males and females, or between those with English as first or second language?
t.test(Shipley_Voc_Score ~ english_status, data = dat2 )
Welch Two Sample t-test
data: Shipley_Voc_Score by english_status
t = 1.1382, df = 6.207, p-value = 0.2971
alternative hypothesis: true difference in means between group ESL and group native is not equal to 0
95 percent confidence interval:
-8.672518 23.986804
sample estimates:
mean in group ESL mean in group native
41.85714 34.20000
cohensD(Shipley_Voc_Score ~ english_status, method ="unequal", data = dat2 )
[1] 0.6025947
For the eagle-eyed among you, you might notice that some of the scores are outside the possible range - these typos often occur in data, and should be filtered out. What is the result if you do the filtering?
The data from this paper are called ClassDraw.csv available here. The data are on osf as well, but they’re not formatted in a very accessible way, so I adjusted them and put them here.
Jalava, S. T., Wammes, J. D., & Cheng, K. (2023). Drawing your way to an A: Long-lasting improvements in classroom quiz performance following drawing. Psychonomic Bulletin & Review, 30, 1939–1945. https://doi.org/10.3758/s13423-023-02294-2
There are some useful tips in the results of this study about the benefit of doodling…
My challenge to you:
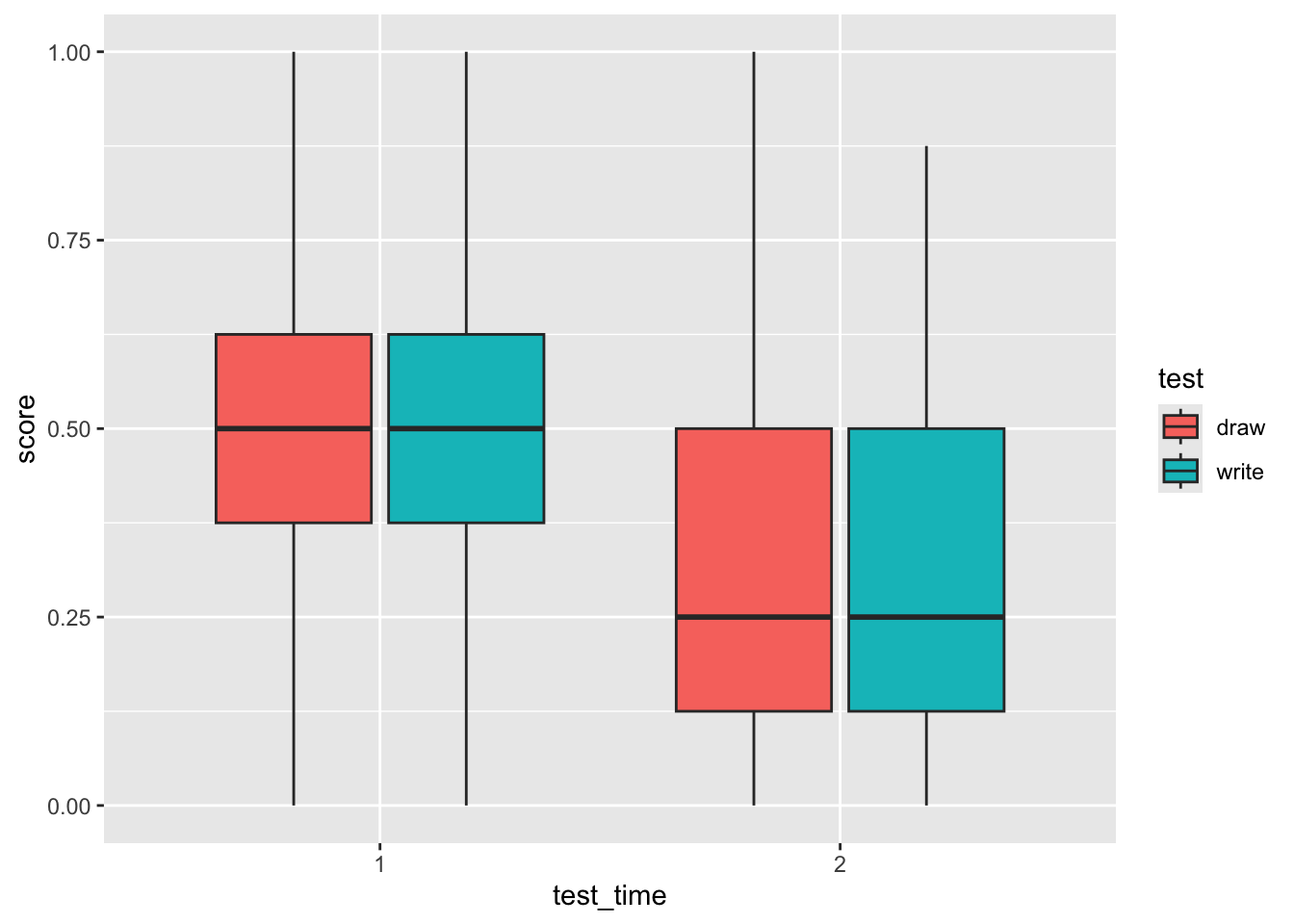
Can you make a ggplot that looks a bit like Figure 2 from this study?
Answer
jalava <-read_csv("data/wk5/ClassDraw.csv")
Rows: 168 Columns: 9
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Gender
dbl (8): ID, Age, write_1, write_2, draw_1, draw_2, exam_draw, exam_write
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning: Removed 48 rows containing non-finite outside the scale range
(`stat_boxplot()`).
# median looks very similar (boxplots very overlapping), but means are a bit different:jalava2 %>%group_by(test, test_time) %>%summarise(mean(score, na.rm=TRUE), sd(score, na.rm=TRUE))
`summarise()` has grouped output by 'test'. You can override using the
`.groups` argument.
If you’ve made some progress on the de Zubicaray et al. (2024) data analysis, to the point where you have replicated (more or less) the multiple regression analysis from the first study in that paper, then here is the next step.
Note, this is a major challenge, but it will be a step into new research!
The task is to take the de Zubicaray data, and add a new variable which determines whether the word is a palindrome or not. A palindrome is a word that is spelled the same backwards as forwards (e.g., abba, rotavator).
I would like to know if being a palindrome or not affects processing of the words. My prediction is that being a palindrome helps access the word.
What you will need to do is apply a function called “palindrome” to the words in the de Zubicaray dataset, to make a new variable, called or some other name then run a multiple regression with all the other variables plus this one.
Here is a script with the function called palindrome included, with some comments to show how it is put into practice. You will need to add the function into the top of an analysis script (e.g., rmd or r script) file and make sure that is loaded along with the other commands you are using.